这篇文章本来是 Jim 在 2022 年 9 月份面试清华大学研究生会清研学术讲师团时写的稿子,主要围绕 Jim 设计的一套《Python 数据分析》课程其中的《网络数据获取技术》这一讲进行的讲解。但是经历了一年的课程讲授,以及后来与同学们的答疑讨论,Jim 越来越觉得这篇文章应该重写,重写的目的是为新手从 HTTP 底层到 Python 实践全链条地讲解 Python 爬虫。
你看到的网页是以什么方式呈现的?
我们举个例子,假如我们在 Chrome 浏览器的地址栏内键入 https://www.baidu.com,右键点击检查(快捷键 Ctrl+Shift+I for Windows, Command+Shift+I for MacOS,对于 Safari 浏览器,检查/审查元素需要在偏好设置里开启),会出现一个让人不明所以的窗格,里面有几个标签页,比如 Network, Resources 等,其实每个标签页都指的是不同内容,比如 Network 标签页指的是网页瀑布,Resources 指的是网页加载附带的文件(如 JavaScript 脚本、CSS 样式表以及图片、字体等),而我们看到的网页,其实包含的内容在 Elements(元素)页。
点开 Elements 页,我们能看到一大堆被 <balabala></balabala> 的文本,这是以 HTML(Hypertext Markup Language,超文本标记语言)的形式呈现的。
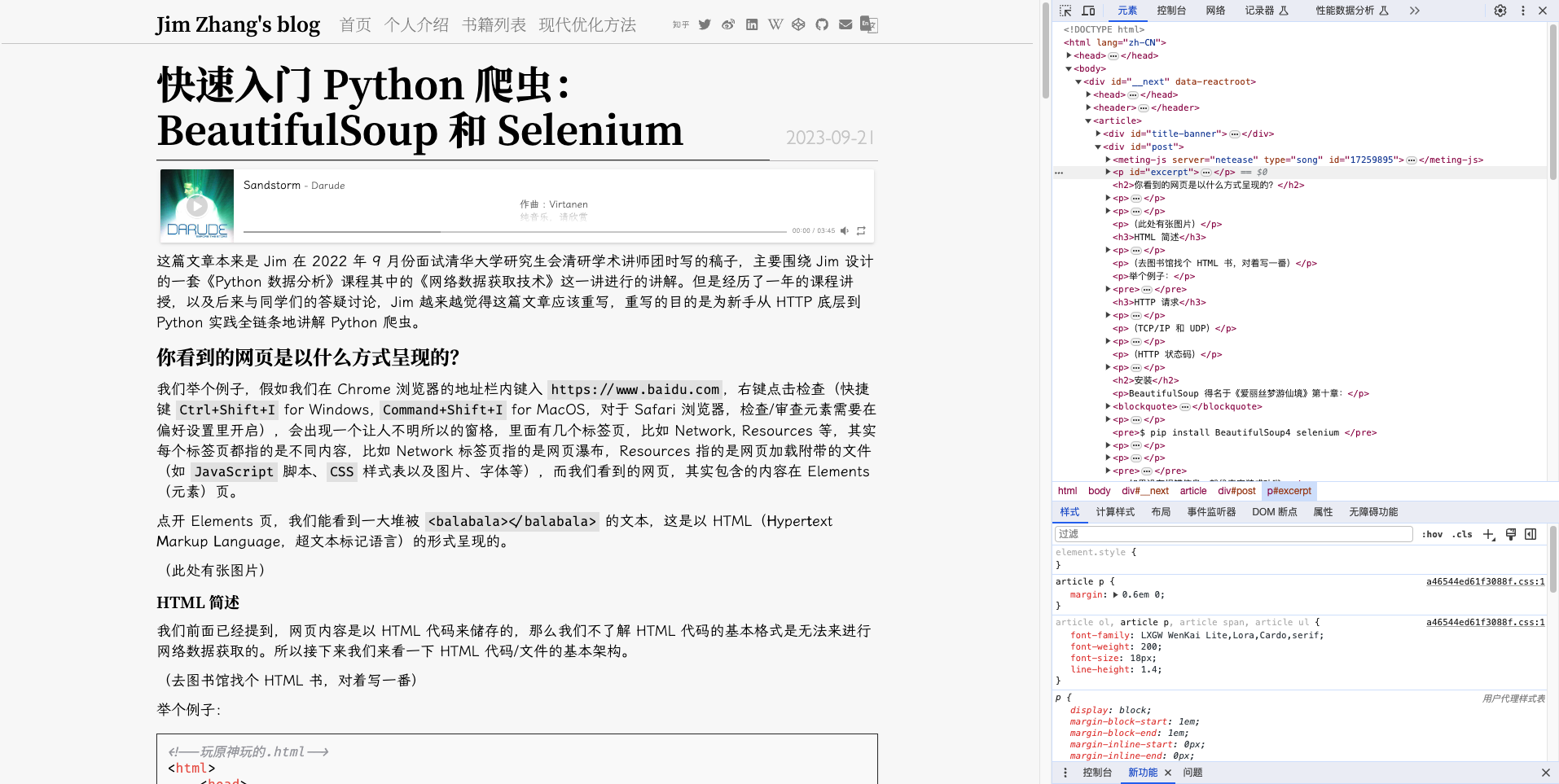
而在右边,
HTML 简述
我们前面已经提到,网页内容是以 HTML 代码来储存的,那么我们不了解 HTML 代码的基本格式是无法来进行网络数据获取的。所以接下来我们来看一下 HTML 代码/文件的基本架构。
(去图书馆找个 HTML 书,对着写一番)
举个例子:
<!--玩原神玩的.html-->
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no">
<title>原神,启动!</title>
</head>
<body>
<h1>上海米哈游天命科技有限公司</h1>
<p>你说得对,但是《原神》是由米哈游自主研发的一款全新开放世界冒险游戏。游戏发生在一个被称作【提瓦特】的幻想世界,在这里,被神选中的人将被授予【神之眼】,导引元素之力。你将扮演一位名为【旅行者】的神秘角色,在自由的旅行中邂逅性格各异、能力独特的同伴们,和他们一起击败强敌,找回失散的亲人——同时逐步发掘【原神】的真相。。。</p>
</body>
<script>
console.log("卧石山里灵活的狗!");
</script>
</html>
HTTP 请求
HTTP(Hypertext Transfer Protocol,超文本传输协议)这四个字母大家肯定都见过。只能说,每天见不到这四个字母的只能是根本不上网的人。(因为地址栏里肯定不是 http:// 就是 https:// 啊!)
(TCP/IP 和 UDP)
HTTP 请求有以下七种,常见的请求有 GET 和 POST 两种。
| 方法 | 描述 | 是否包含请求体 |
|---|---|---|
GET | 请求指定的页面信息,并返回实体主体。 | 否 |
HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 | 否 |
POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 | 是 |
PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 | 是 |
TRACE | 对可能经过代理服务器传送到服务器的报文进行追踪。 | 否 |
OPTION | 决定可以支持的请求方法,或者对服务器的某些资源是否可用。 | 否 |
DELETE | 请求服务器删除指定的页面。 | 否 |
(HTTP 状态码)
(俺的 nginx 日志)
安装
BeautifulSoup 得名于《爱丽丝梦游仙境》第十章:
Beautiful Soup, so rich and green,
Waiting in a hot tureen!
Who for such dainties would not stoop?
Soup of the evening, beautiful Soup!
Soup of the evening, beautiful Soup!
...
Chapter 10, Alice's Adventures in Wonderland, Lewis Carroll.
意为“化腐朽为神奇”。BeautifulSoup 和 Selenium 的安装很方便,只需要一行命令:
$ pip install BeautifulSoup4 selenium
请注意,不是 pip install BeautifulSoup,而是 pip install BeautifulSoup4,因为前者指的是 BeautifulSoup3。
安装完成后,我们可以通过 python 交互式控制台来检验是否成功安装,比如:
Python 3.10.7 (tags/v3.10.7:6cc6b13, Sep 5 2022, 14:08:36) [MSC v.1933 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> from bs4 import BeautifulSoup, import selenium >>>
如果没有报错信息,就代表安装成功啦。
BeautifulSoup
本地 html 文件
首先,我们可以先用一个本地 html 文件做测试,这个文件内容如下:
<!--test.html-->
<html>
<head>
<title>这是测试。</title>
</head>
<body>
<h1>Test</h1>
<p>这是一个测试。</p>
<p>这是第二个测试。</p>
</body>
</html>
它对应的 DOM(Document Object Model,文档对象模型)树如下:
Document
└── html
├── head
│ └── title
└── body
├── h1
├── p
└── p
这个树形结构为我们讲述了如下信息:
Document是整个文档的根节点,它的子节点是html。html是文档的根元素,它的子节点是head、body等。head是文档的头部,它的子节点是title等。body是文档的主体,它的子节点是h1、p等。title、h1、p等都是文档的叶子节点,它们没有子节点。
然后,我们可以通过 BeautifulSoup 来读取这个文件,代码如下:
from bs4 import BeautifulSoup
with open('test.html', 'r', encoding='utf-8') as f:
soup = BeautifulSoup(f, 'html.parser')
print(soup.prettify())
输出结果如下:
<html> <head> <title> 这是测试。 </title> </head> <body> <h1> Test </h1> <p> 这是一个测试。 </p> <p> 这是第二个测试。 </p> </body> </html>
这样,我们就可以通过 soup 来访问这个 html 文件了。进一步地,我们可以通过 soup 来访问它的子节点,比如:
print(soup.html.head.title)
输出结果如下:
<title>这是测试。</title>
我们可以看到,soup.html.head.title 就是 title 节点,对于整个文档唯一的节点(title 就是这样),我们可以通过 soup.title 来直接访问它。但是对于非唯一的节点就比较麻烦,比如第一个 p 节点,我们可以通过 soup.body.p 来访问它,但是如果我们想要访问第二个 p 节点,就没办法了。这时候,我们可以通过 find_all 方法来访问它们,比如:
print(soup.find_all('p'))
输出结果如下:
[<p>这是一个测试。</p>, <p>这是第二个测试。</p>]
获取标签中的内容,对每个 tag 使用 text 属性即可,比如:
print(soup.title.text)
输出结果如下:
这是测试。
网页
接下来,我们来看看如何使用 BeautifulSoup 来爬取网页。首先,为了利用 python 帮我们完成发送请求的操作,我们需要导入 requests 库(安装方法我们就不重复介绍了),然后通过 requests 来获取网页的内容。
现在有这样一个网页:https://q-weather.info/weather/54399/history/?date=2022-09-16,其内容大致如下
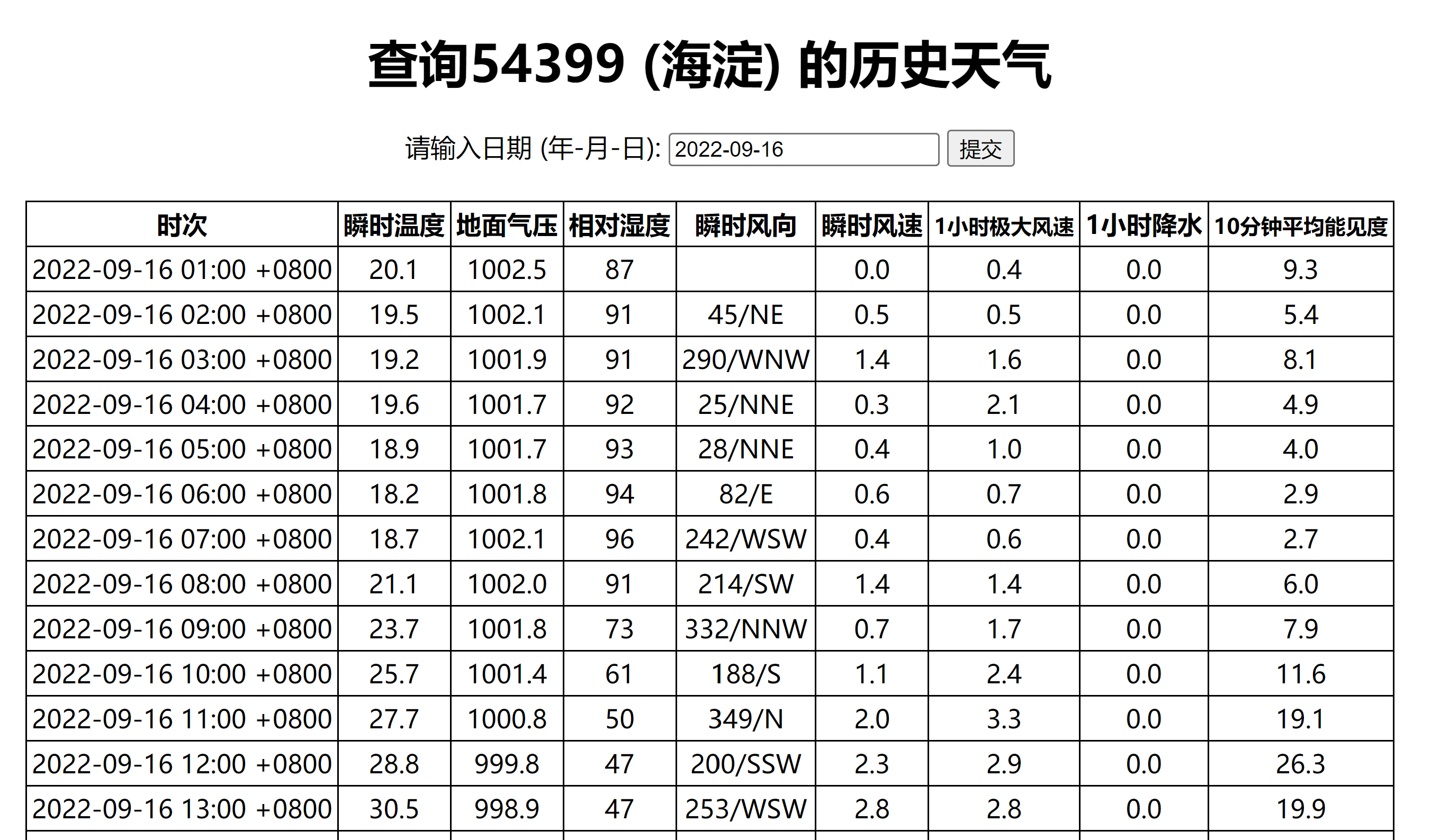
存储了海淀区的天气信息。现在想获取这个网页数据,我们如下操作:
import requests, pandas as pd
from bs4 import BeautifulSoup
url = 'https://q-weather.info/weather/54399/history/'
params = {'date': '2022-09-16'}
r = requests.get(url, params=params)
soup = BeautifulSoup(r.text, 'html.parser')
这样这个 soup 就存储这个网页的内容了。接下来的任务显而易见:首先获取表格的标题行,然后是数据单元格,最后是把他们存储起来。
table = soup.table
columns = [th.text for th in table.thead.find_all('th')]
data = [[td.text for td in tr.find_all('td')] for tr in table.tbody.find_all('tr')]
df = pd.DataFrame(data, columns=columns)
print(df.head)
输出结果如下:
时次 瞬时温度 地面气压 相对湿度 瞬时风向 瞬时风速 1小时极大风速 1小时降水 10分钟平均能见度 0 2022-09-16 01:00 +0800 20.1 1002.5 87 0.0 0.4 0.0 9.3 1 2022-09-16 02:00 +0800 19.5 1002.1 91 45/NE 0.5 0.5 0.0 5.4 2 2022-09-16 03:00 +0800 19.2 1001.9 91 290/WNW 1.4 1.6 0.0 8.1 3 2022-09-16 04:00 +0800 19.6 1001.7 92 25/NNE 0.3 2.1 0.0 4.9 4 2022-09-16 05:00 +0800 18.9 1001.7 93 28/NNE 0.4 1.0 0.0 4.0
这就是 BeautifulSoup 的基本用法了,更多的用法可以参考官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Selenium
Selenium 是一个自动化测试工具,它可以模拟浏览器的操作,比如点击、输入、滚动等等。它的主要功能是自动化测试,但是它也可以用来爬取网页。它的优点是可以模拟浏览器的操作,可以模拟人的操作,比如滚动、点击等等,这样就可以爬取一些动态加载的网页了。
安装
前文已经提到了 Selenium 的安装方法,这里就不再重复介绍了。但是除了安装 Selenium 之外,我们还需要安装一个浏览器驱动,这个驱动的作用是让 Selenium 可以控制浏览器。这里我们以 Chrome 浏览器为例,安装 Chrome 浏览器驱动。(Edge 浏览器的话需要额外安装 msedge-selenium-tools)
Windows
在 https://sites.google.com/chromium.org/driver/ 下载对应版本的 Chrome 浏览器驱动,并将其目录添加到 PATH 环境变量中即可。
Mac OS & Linux
在 Mac OS 和 Linux 上安装 Chrome 浏览器驱动比较简单,利用包管理器安装就可以了。
# Mac OS
brew install chromedriver
# Linux (debian-like)
sudo apt-get install chromedriver
使用
Selenium 的使用方法很简单,首先导入 Selenium 的 webdriver 模块,然后创建一个 webdriver 对象,这个对象就是浏览器的控制器,然后就可以通过这个对象来控制浏览器了。
from selenium import webdriver
driver = webdriver.Chrome()
注意,这里请确保你的 chromedriver 的版本和你的 Chrome 浏览器的版本是一致的,且 chromedriver 要在 PATH 环境变量中(否则要指定路径)。
然后就是访问网页了,这里我们还是以前面的例子为例,访问 https://q-weather.info/weather/54399/history/?date=2022-09-16。
driver.get('https://q-weather.info/weather/54399/history/?date=2022-09-16')
chromedriver 会自动打开一个 Chrome 浏览器窗口,然后访问指定的网页。
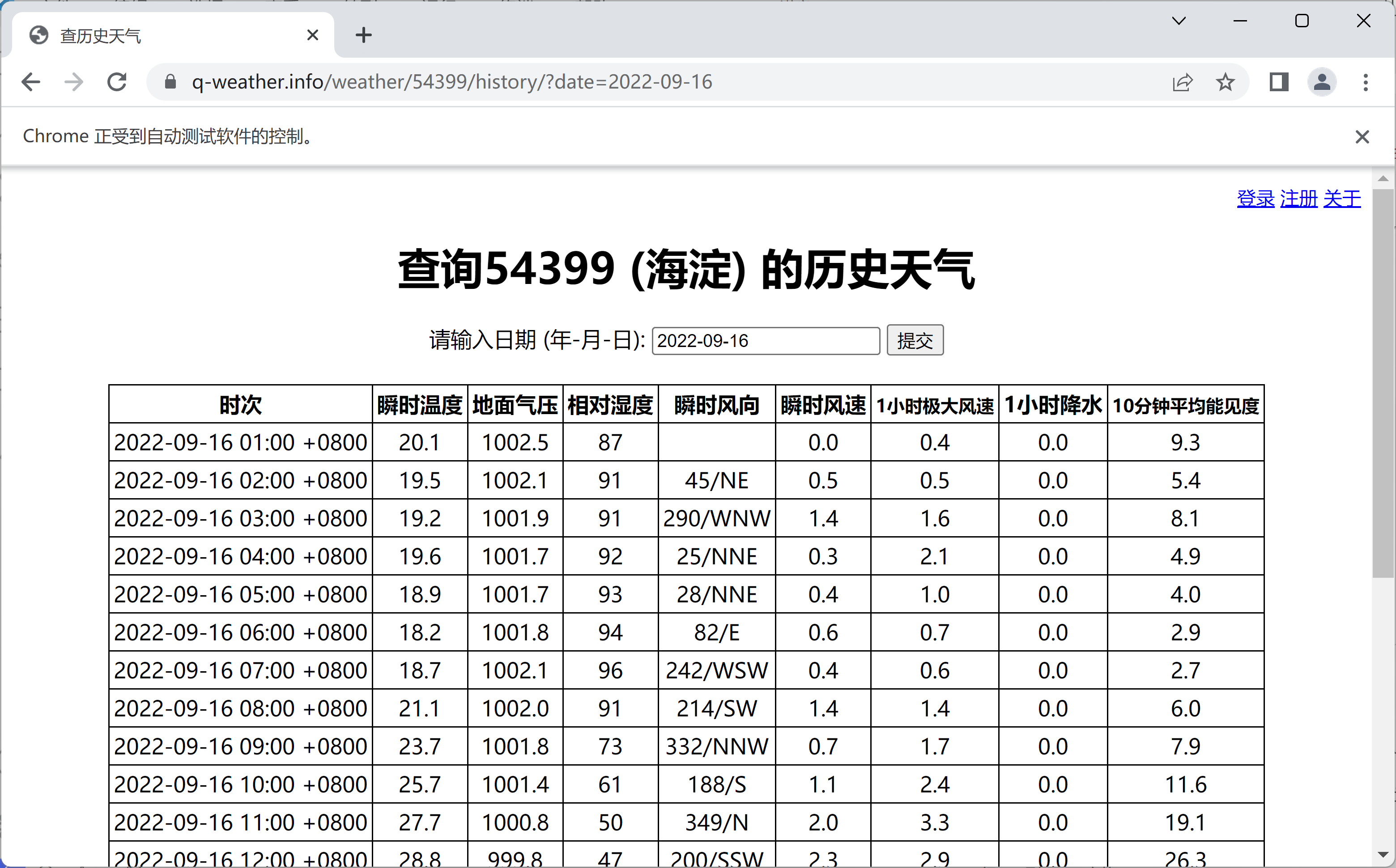
然后我们就可以通过 Selenium 来获取网页存储的数据了。这里我们可以通过 find_element_by_id 方法来获取指定 id 的元素,然后通过 text 属性来获取元素的文本内容。