这篇文章主要介绍了如何使用 Python 爬虫获取 2000-2023 年 Billboard Hot 100 每周榜单数据。
写在前面:2024 新年快乐!
在 2024 年的第一天写这篇文章真的非常感慨,在过去的 2023 年里,Jim 最感动的事情是加入了清华大学学生电子音乐协会,弥补了本科在北航没有组建起电子音乐社团的遗憾。而同样,Robert Miles 的专辑《Dreamland》也正是在电音社的百团大战摊位上被 Jim 发现,Jim 才毅然决然地加入了电音社。这张专辑的《Children》正是火遍全球的经典电音,下面的八小节旋律也名扬天下:
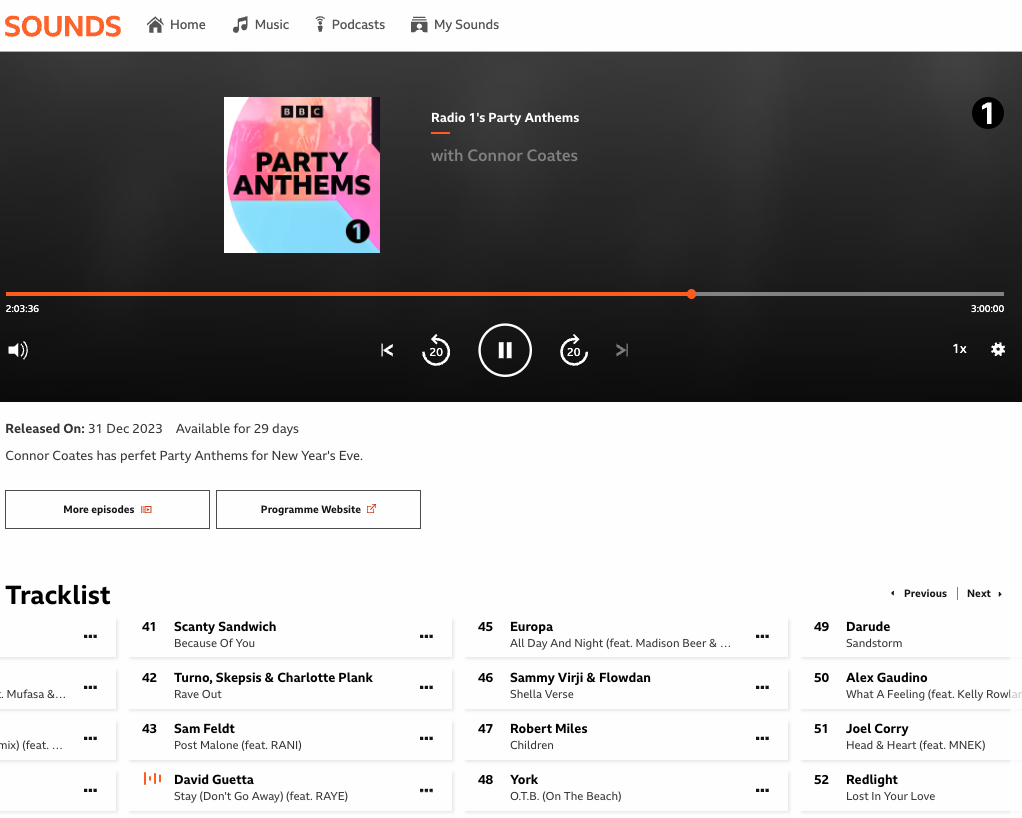
就在 1 月 1 日 大约 2 点钟(伦敦时间 2023 年 12 月 31 日约 18 点钟)的时候,BBC Radio 1 的 Conner Coates 也在节目中播放了这首经典的《Children》,这也是 Jim 在 2024 年第一件开心的事情!
工作动机
有一天 Jim 在听这个:
结果满脑子都涌现出高中时候的回忆,又感慨现在的流行音乐真的不如以前好听了,于是就想着能不能把以前的音乐都找出来听听,就想能不能把整个 21 世纪的 Billboard Hot 100 榜单都爬下来,然后再把这些歌曲放到一个流媒体平台(Spotify or Apple Music)的播放列表上面,这样就可以随时随地听到以前的歌曲了。
比如这样:
爬虫工作
读者可以自己试一下,Billboard 的官网是不接受爬虫的,所以我们需要使用 Selenium 来模拟浏览器的行为,这样就可以绕过 Billboard 的反爬虫机制了。
调用
Jim 曾在其他地方写过 Selenium 的教程,这里就不再赘述了,直接看调用部分:
import datetime
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
获取榜单日期
Billboard 的榜单是每周六更新的:
Generally, charts reflect sales and airplay between Friday and Thursday of any given week.
Charts are refreshed every Tuesday on Billboard.com and reflect the date of the Billboard issue in which they appear; online-only charts display the same corresponding date.
The printed magazine first reaches newsstands on Saturday. Each issue is dated based on the end of its publication week. Thus, the Billboard that reaches newsstands on Saturday, March 19, for example, is dated that day.
所以我们只需要获取每周六的日期就可以了(注意:2000 年 1 月 1 日碰巧是周六),这里使用了 Python 的 datetime 模块:
def get_saturdays(self):
self.start_date = datetime.date(2000, 1, 1)
self.end_date = datetime.date(2023, 12, 20)
current_date = self.start_date
saturdays = []
while current_date <= self.end_date:
if current_date.weekday() == 5:
saturdays.append(current_date.strftime('%Y-%m-%d'))
current_date += datetime.timedelta(days=1)
return saturdays
获取榜单数据
这一部分是最核心的部分,我们需要获取每周榜单的前 100 名,这里使用了 Selenium 的 WebDriverWait 来等待页面加载完成,然后再获取数据:
def get_entries(self, date: str) -> list:
"""
Returns a list of entries of *Billboard 100* for a given date.
### Args
date (YYYY-MM-DD): The date to get entries for
"""
self.driver.get(f"https://www.billboard.com/charts/hot-100/{date}")
chart = WebDriverWait(self.driver, 5).until(
EC.presence_of_element_located((By.CLASS_NAME, "chart-results-list"))
)
records_title = self.driver.find_element_by_css_selector("h3.lrv-u-margin-r-150")
records_title_excluding_first = chart.find_elements_by_css_selector("h3.u-max-width-330")
records_artist = chart.find_elements_by_css_selector("span.u-max-width-330")
entries = []
for i in range(len(records_title_excluding_first) + 1):
if i == 0:
entries.append([i+1, records_title.text, records_artist[i].text])
else:
entries.append([i+1, records_title_excluding_first[i-1].text, records_artist[i].text])
return entries
(补充说明数据存储机制)
写成 class
最后,我们把上面的代码加上一些存储的功能写成一个 class,这样就可以直接调用了:
class BillBoardScraper:
def __init__(self) -> None:
self.driver = webdriver.Chrome()
pass
def get_saturdays(self):
self.start_date = datetime.date(2018, 9, 15)
self.end_date = datetime.date(2023, 12, 20)
current_date = self.start_date
saturdays = []
while current_date <= self.end_date:
if current_date.weekday() == 5:
saturdays.append(current_date.strftime('%Y-%m-%d'))
current_date += datetime.timedelta(days=1)
return saturdays
def get_entries(self, date: str) -> list:
"""
Returns a list of entries of *Billboard 100* for a given date.
### Args
date (YYYY-MM-DD): The date to get entries for
"""
self.driver.get(f"https://www.billboard.com/charts/hot-100/{date}")
chart = WebDriverWait(self.driver, 5).until(
EC.presence_of_element_located((By.CLASS_NAME, "chart-results-list"))
)
records_title = self.driver.find_element_by_css_selector("h3.lrv-u-margin-r-150")
records_title_excluding_first = chart.find_elements_by_css_selector("h3.u-max-width-330")
records_artist = chart.find_elements_by_css_selector("span.u-max-width-330")
entries = []
for i in range(len(records_title_excluding_first) + 1):
if i == 0:
entries.append([i+1, records_title.text, records_artist[i].text])
else:
entries.append([i+1, records_title_excluding_first[i-1].text, records_artist[i].text])
return entries
def save_entries(self, entries, date):
"""
Saves entries to a csv file
Args:
entries (list): List of entries to save
date (YYYY-MM-DD): Date of the entries
"""
df = pd.DataFrame(entries, columns=['rank', 'title', 'artist'])
df.to_csv(f"data/{date}.csv", index=False)
def run(self):
saturdays = self.get_saturdays()
for saturday in saturdays:
entries = self.get_entries(saturday)
self.save_entries(entries, saturday)
self.driver.quit()
if __name__ == "__main__":
scraper = BillBoardScraper()
scraper.run()
总结
这篇文章主要介绍了如何使用 Python 爬虫获取 2000-2023 年 Billboard Hot 100 每周榜单数据。Jim 也把这些数据放到了 GitHub 上面,大家可以自行下载:2000-2023 Billboard Top 100 Songs